반응형

Language모델의 문장 생성 순서
- 확률이 가장 높은 단어 선택
- 결과 일정
- 확률적 선택
- 각 후보 단어의 확률에 맞게 선택
- 샘플링 되는 단어 매번 바뀜
- 확률분포 출력, 샘플링을 반복


import numpy as np
def softmax(x):
if x.ndim == 2:
x = x - x.max(axis=1, keepdims=True)
x = np.exp(x)
x /= x.sum(axis=1, keepdims=True)
elif x.ndim == 1:
x = x - np.max(x)
x = np.exp(x) / np.sum(np.exp(x))
return x
class BaseModel:
def __init__(self):
self.params, self.grads = None, None
def forward(self, *args):
raise NotImplementedError
def backward(self, *args):
raise NotImplementedError
def save_params(self, file_name=None):
if file_name is None:
file_name = self.__class__.__name__ + '.pkl'
params = [p.astype(np.float16) for p in self.params]
if GPU:
params = [to_cpu(p) for p in params]
with open(file_name, 'wb') as f:
pickle.dump(params, f)
def load_params(self, file_name=None):
if file_name is None:
file_name = self.__class__.__name__ + '.pkl'
if '/' in file_name:
file_name = file_name.replace('/', os.sep)
if not os.path.exists(file_name):
raise IOError('No file: ' + file_name)
with open(file_name, 'rb') as f:
params = pickle.load(f)
params = [p.astype('f') for p in params]
if GPU:
params = [to_gpu(p) for p in params]
for i, param in enumerate(self.params):
param[...] = params[i]
class Rnnlm(BaseModel):
def __init__(self, vocab_size=10000, wordvec_size=100, hidden_size=100):
V, D, H = vocab_size, wordvec_size, hidden_size
rn = np.random.randn
# 가중치 초기화
embed_W = (rn(V, D) / 100).astype('f')
lstm_Wx = (rn(D, 4 * H) / np.sqrt(D)).astype('f')
lstm_Wh = (rn(H, 4 * H) / np.sqrt(H)).astype('f')
lstm_b = np.zeros(4 * H).astype('f')
affine_W = (rn(H, V) / np.sqrt(H)).astype('f')
affine_b = np.zeros(V).astype('f')
# 계층 생성
self.layers = [
TimeEmbedding(embed_W),
TimeLSTM(lstm_Wx, lstm_Wh, lstm_b, stateful=True),
TimeAffine(affine_W, affine_b)
]
self.loss_layer = TimeSoftmaxWithLoss()
self.lstm_layer = self.layers[1]
# 모든 가중치와 기울기를 리스트에 모은다.
self.params, self.grads = [], []
for layer in self.layers:
self.params += layer.params
self.grads += layer.grads
def predict(self, xs):
for layer in self.layers:
xs = layer.forward(xs)
return xs
def forward(self, xs, ts):
score = self.predict(xs)
loss = self.loss_layer.forward(score, ts)
return loss
def backward(self, dout=1):
dout = self.loss_layer.backward(dout)
for layer in reversed(self.layers):
dout = layer.backward(dout)
return dout
def reset_state(self):
self.lstm_layer.reset_state()
class BetterRnnlm(BaseModel):
'''
LSTM 계층을 2개 사용하고 각 층에 드롭아웃을 적용한 모델이다.
아래 [1]에서 제안한 모델을 기초로 하였고, [2]와 [3]의 가중치 공유(weight tying)를 적용했다.
[1] Recurrent Neural Network Regularization (https://arxiv.org/abs/1409.2329)
[2] Using the Output Embedding to Improve Language Models (https://arxiv.org/abs/1608.05859)
[3] Tying Word Vectors and Word Classifiers (https://arxiv.org/pdf/1611.01462.pdf)
'''
def __init__(self, vocab_size=10000, wordvec_size=650,
hidden_size=650, dropout_ratio=0.5):
V, D, H = vocab_size, wordvec_size, hidden_size
rn = np.random.randn
embed_W = (rn(V, D) / 100).astype('f')
lstm_Wx1 = (rn(D, 4 * H) / np.sqrt(D)).astype('f')
lstm_Wh1 = (rn(H, 4 * H) / np.sqrt(H)).astype('f')
lstm_b1 = np.zeros(4 * H).astype('f')
lstm_Wx2 = (rn(H, 4 * H) / np.sqrt(H)).astype('f')
lstm_Wh2 = (rn(H, 4 * H) / np.sqrt(H)).astype('f')
lstm_b2 = np.zeros(4 * H).astype('f')
affine_b = np.zeros(V).astype('f')
self.layers = [
TimeEmbedding(embed_W),
TimeDropout(dropout_ratio),
TimeLSTM(lstm_Wx1, lstm_Wh1, lstm_b1, stateful=True),
TimeDropout(dropout_ratio),
TimeLSTM(lstm_Wx2, lstm_Wh2, lstm_b2, stateful=True),
TimeDropout(dropout_ratio),
TimeAffine(embed_W.T, affine_b) # weight tying!!
]
self.loss_layer = TimeSoftmaxWithLoss()
self.lstm_layers = [self.layers[2], self.layers[4]]
self.drop_layers = [self.layers[1], self.layers[3], self.layers[5]]
self.params, self.grads = [], []
for layer in self.layers:
self.params += layer.params
self.grads += layer.grads
def predict(self, xs, train_flg=False):
for layer in self.drop_layers:
layer.train_flg = train_flg
for layer in self.layers:
xs = layer.forward(xs)
return xs
def forward(self, xs, ts, train_flg=True):
score = self.predict(xs, train_flg)
loss = self.loss_layer.forward(score, ts)
return loss
def backward(self, dout=1):
dout = self.loss_layer.backward(dout)
for layer in reversed(self.layers):
dout = layer.backward(dout)
return dout
def reset_state(self):
for layer in self.lstm_layers:
layer.reset_state()
class RnnlmGen(Rnnlm):
def generate(self, start_id, skip_ids = None, sample_size = 100): # 문장 생성
# start_id : 최초 단어의 ID, sample_size : 샘플링 하는 단어의 수, skip_ids : 단어 ID의 리스트
word_ids = [start_id]
x = start_id
while len(word_ids) < sample_size:
x = np.array(x).reshape(1,1)
score = self.predict(x)
p = softmax(score.flatten())
sampled = np.random.choice(len(p), size = 1, p=p)
if(skip_ids is None) or (sampled not in skip_ids):
x = sampled
word_ids.append(int(x))
return word_ids
seq2seq
- 시계열 데이터를 다른 시계열 데이터로 변환
- Encoder(입력 데이터의 부호화)-Decoder(인코딩된 데이터의 복호화) 모델
# 인코딩 - 정보를 어떤 큐칙에 따라 변환 // 디코딩 - 인코딩된 정보를 원래의 정보로 되돌리는 변환

Encoder

RNN을 이용, 시계열 데이터(임의 길이)를 hidden state vector(고정 길이) 로 변환
마지막 hidden state(h) 에 입력된 문장 번역시 필요한 정보 인코딩
Decoder
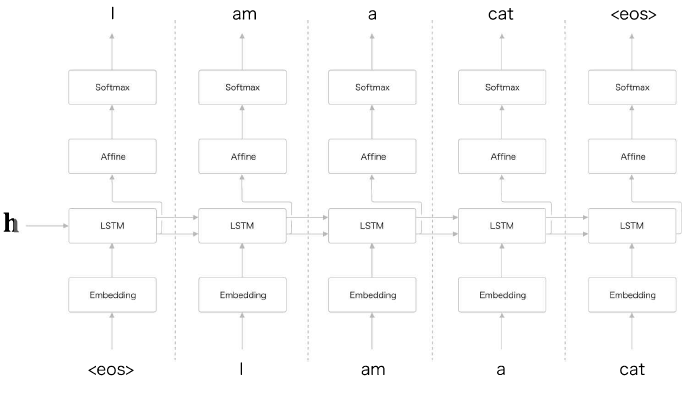
기존 신경망 구성LSTM 계층이 vector h 를 입력받음
# eos - Decoder 문장 생성의 시작/종료 구분자

seq2seq2 - Encoder, Decoder LSTM으로 구성(hidden state를 통해 기울기 전달)
seq2seq 구현
- 2개의(Encoder, Decoder) RNN 연결
- Encoder에서 hidden state를 Decoder에 전달
- vocab_size - 어휘 수
- wordvec_size - 문자 벡터의 차원 수
- hidden_size - LSTM 계층의 은닉 상태 벡터 차원 수
- dh - LSTM 계층의 마지막 은닉 상태에 대한 기울기 (디코더가 전해주는 기울기)
- dhs(역전파시) - 원소가 모두 0인 텐서
짧은 시계열 여러개를 입력받기 때문에 은닉상태 초기화 상태로 지정 stateful = False


# coding: utf-8
import sys
sys.path.append('..')
import os
import pickle
import numpy as np
class BaseModel:
def __init__(self):
self.params, self.grads = None, None
def forward(self, *args):
raise NotImplementedError
def backward(self, *args):
raise NotImplementedError
def save_params(self, file_name=None):
if file_name is None:
file_name = self.__class__.__name__ + '.pkl'
params = [p.astype(np.float16) for p in self.params]
if GPU:
params = [to_cpu(p) for p in params]
with open(file_name, 'wb') as f:
pickle.dump(params, f)
def load_params(self, file_name=None):
if file_name is None:
file_name = self.__class__.__name__ + '.pkl'
if '/' in file_name:
file_name = file_name.replace('/', os.sep)
if not os.path.exists(file_name):
raise IOError('No file: ' + file_name)
with open(file_name, 'rb') as f:
params = pickle.load(f)
params = [p.astype('f') for p in params]
if GPU:
params = [to_gpu(p) for p in params]
for i, param in enumerate(self.params):
param[...] = params[i]
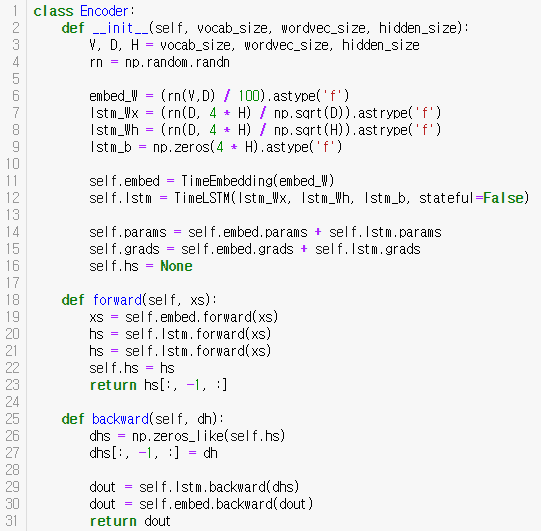
class Encoder:
def __init__(self, vocab_size, wordvec_size, hidden_size):
V, D, H = vocab_size, wordvec_size, hidden_size
rn = np.random.randn
embed_W = (rn(V,D) / 100).astype('f')
lstm_Wx = (rn(D, 4 * H) / np.sqrt(D)).astrype('f')
lstm_Wh = (rn(D, 4 * H) / np.sqrt(H)).astrype('f')
lstm_b = np.zeros(4 * H).astype('f')
self.embed = TimeEmbedding(embed_W)
self.lstm = TimeLSTM(lstm_Wx, lstm_Wh, lstm_b, stateful=False)
self.params = self.embed.params + self.lstm.params
self.grads = self.embed.grads + self.lstm.grads
self.hs = None
def forward(self, xs):
xs = self.embed.forward(xs)
hs = self.lstm.forward(xs)
hs = self.lstm.forward(xs)
self.hs = hs
return hs[:, -1, :]
def backward(self, dh):
dhs = np.zeros_like(self.hs)
dhs[:, -1, :] = dh
dout = self.lstm.backward(dhs)
dout = self.embed.backward(dout)
return dout
class Decoder:
def __init__(self, vocab_size, wordvec_size, hidden_size):
V,D,H = vocab_size, wordvec_size, hidden_size
rn = np.random.randn
embed_W = (rn(V,D) / 100).astype('f')
lstm_Wx = (rn(D, 4 * H) / np.sqrt(D)).astrype('f')
lstm_Wh = (rn(D, 4 * H) / np.sqrt(H)).astrype('f')
lstm_b = np.zeros(4 * H).astype('f')
affine_W = (rn(H, V) / np.sqrt(H)).astype('f')
affine_b = np.zeros(V).astype('f')
self.embed = TimeEmbedding(embed_W)
self.lstm = TimeLSTM(lstm_Wx, lstm_Wh, lstm_b, stateful = True)
self.affine = TimeAffine(affine_W, affine_b)
self.params, self.grads = [], []
for layer in (self.embed, self.lstm, self.affine):
self.parmas += layer.params
self.grads += layer.grads
def forward(self, xs, h):
self.lstm.set_state(h)
out = self.embed.forward(xs)
out = self.lstm.forward(out)
score = self.affine.forward(out)
return score
def backward(self, dscore):
dout = self.affine.backward(dscore)
dout = self.lstm.backward(dout)
dout = self.emebd.ackward(dout)
dh = self.lsmt.dh
return dh
def generate(self, h, start_id, sample_size):
sampled = []
sample_id = start_id
self.lstm.set_state(h)
for _ in range(sample_size):
x = np.array(sample_id).reshape((1, 1))
out = self.embed.forward(x)
out = self.lstm.forward(out)
score = self.affine.forward(out)
sample_id = np.argmax(score.flatten())
sampled.append(int(sample_id))
return sampled
class Seq2seq(BaseModel):
def __init__(self, vocab_size, wordvec_size, hidden_size):
V,D,H = vocab_size, wordvec_size, hidden_size
self.encoder = Encoder(V, D, H)
self.decoder = Encoder(V, D, H)
self.softmax = TimeSoftmaxWithLoss()
self.params = self.encoder.params + self.decoder.params
self.grads = self.encoder.grads + self.decoder.grads
def forward(self,xs, ts):
decoder_xs, decoder_ts = ts[:, :-1], ts[:, 1:]
h = self.encoder.forward(xs)
score = self.decoder.forward(decoder_xs, h)
loss = self.softmax.forward(decoder_xs, h)
loss = self.softmax.forward(score, decoder_ts)
return loss
def backward(self, dout=1):
dout = self.softmax.backward(dout)
dh = self.decoder.backward(dout)
dout = self.encoder.backward(dh)
return dout
def generate(self, xs, start_id, sample_size):
h = self.encoder.forward(xs)
sampled = self.decoder.generate(h, start_id, sample_size)
return sampled
seq2seq 의 학습 속도 개선
- Reverse
- 입력 데이터의 순서 반전
- 입력 문장에 대응하는 변환 후 단어와 가까워 지는 경우가 많이 생겨 기울기가 더 잘 전해짐
- 단어 사이의 평균 거리는 동일
- 입력 데이터의 순서 반전
- Peeky
- 인코더에서 디코더로 전달되는 고정 길이 벡터 h를 디코더의 여러 계층에 전달
- 기존 하나의 LSTM이 소유하던 정보 h를 여러 계층이 공유함으로서 더 좋은 결과의 가능성 커짐
- 인코더에서 디코더로 전달되는 고정 길이 벡터 h를 디코더의 여러 계층에 전달
# 본 게시물은 밑바닥부터 시작하는 딥러닝2를 읽고 작성하였습니다.
반응형
'----------책---------- > 밑바닥부터 시작하는 딥러닝2' 카테고리의 다른 글
| CHAPTER 6 게이트가 추가된 RNN (0) | 2020.02.27 |
|---|---|
| CHAPTER 5 순환 신경망(RNN) (0) | 2020.02.18 |
| CHAPTER 4 word2vec 속도 개선 (0) | 2020.02.06 |
| CHAPTER 3 word2vec (0) | 2020.02.03 |
| CHAPTER2 - 자연어와 단어의 분산 표현 (0) | 2020.01.31 |




댓글