논문 제목 : BERT : Pre training of Deep Bidirectional
Transformers for Language Understanding
2번째로 게시할 글 역시 구글에서 발표한 논문이다.
논문제목에서 나와있는 Transformer는 첫 번째 게시글인 attention is all you need의 모델 이름이다.
즉 attention is all you need의 논문을 참조한 논문이며
Bidrectional(양방향)으로 language를 학습한 논문이다.
또한 당시 language 모델에서 가장 좋은 성능을 보였던 ELMo, OpenAI GPT를 겨냥한 논문으로 보인다.
1. 배경
BERT : Bidirectional Encoder Representations from Transformers
- "Attention is all you nee" - Transformer 구조 사용
- Transformer의 장점 :
- 병렬 처리를 통한 학습 속도의 향상
- pre-training과 fine-tuning시 아키텍처를 다르게 하여 Transfer Learning을 용이하게 구성
- language model을 pre-training 시키는 방법은 크게 2가지
1. Feature-based
- 특정 task를 수행하는 network에 pre-trained language representation을 추가적인 feature로 제공
- 두 개의 network를 붙여 사용
2. Fine-tuning
- task-specific 한 parameter를 최소화하여 pre-trained 된 parameter들을 downstream task 학습을 통해 조금씩 바꿔주는 방식
- 대표적 모델 : Generative Pre-trained Transformer(OpenAI GPT)

위 그림은 각각 BERT, OpenAI GPT, ELMo의 모델 구조.
ELMo(Feature-based) - 단방향의 LSTM으로 구성된 두 개의 모델을 붙여 양방향으로 학습되도록 하는 모델
BERT (본 논문의 모델) - 양방향으로 문자열을 학습되도록 하는 모델
2. BERT
Transformer 기반( 인코더만 사용)

Transformer는 왼쪽의 Encoder와 오른쪽의 Decoder로 구성
BERT에서는 왼쪽의 Encoder 부분만을 사용한다.
#Attention is all you need 참고 바람 taepseon.tistory.com/3?category=814260 #
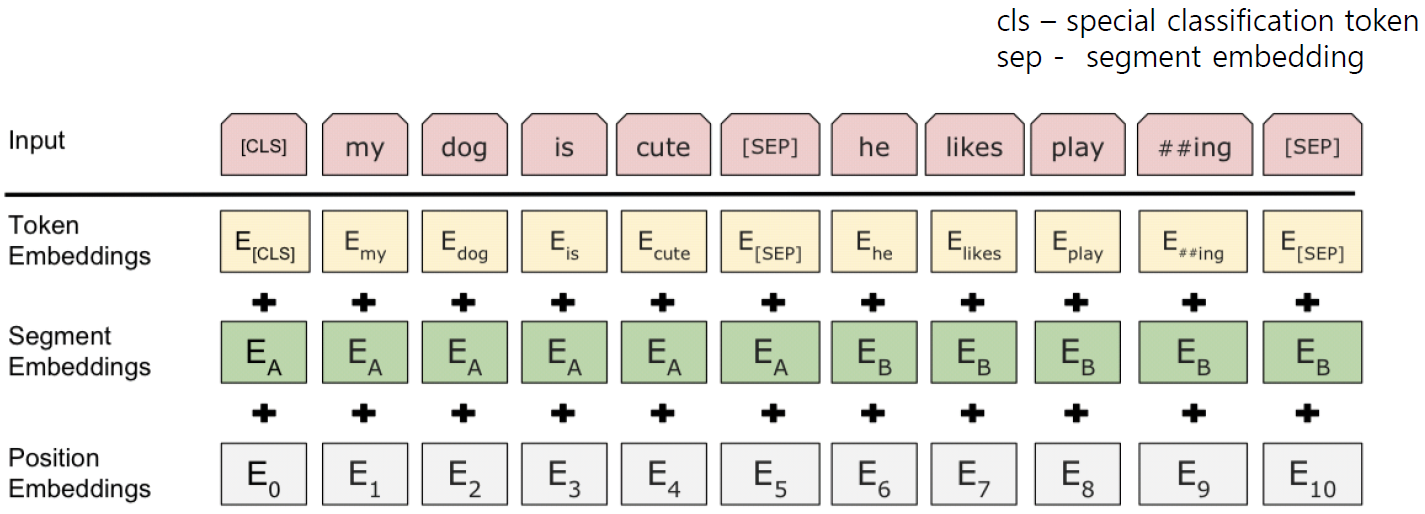
- cls 토큰 - 문장의 시작을 알린다.
- sep 토큰 - 문장의 나뉨을 알린다.
- Token Embeddings - 단어들의 토큰을 이용한 Embedding
- Segment Embeddings - A라는 문장과 B라는 문장을 구별하기 위한 Embedding
- Position Embeddings - 단어들의 위치정보를 이용한 Embedding


Pre-training Tasks - Language model을 학습시키기 위해 필요
- MLM (Masked Language Model)
- 문장 내 랜덤 한 단어를 masking, 예측하도록 하는 방식
- input에서 랜덤 하게 몇 개의 token을 mask
- Transformer 구조에 넣어 주변 단어의 context만을 보고 mask 된 단어 예측
- Input 전체와 mask된 token을 한 번에 Transformer encoder에 넣고 원래 token값을 예
- 문장 내 랜덤 한 단어를 masking, 예측하도록 하는 방식

- 단어중 일부(15%)를 [mask] token으로 변경
- 15% 중 80% token을 [mask]로 변경
- 15% 중 10% token을 random word로 변경
- 15% 중 10% token을 원래의 단어 그대로(실제 관측된 단어에 대한 표상을 bias 해주기 위해)
- NSP (Next Sentence Prediction)
- 두 문장을 pre-training시 같이 넣어 두 문장이 이어지는 문장인지 아닌지를 맞추는 작업
- pre-training시 50:50 비율로 실제 이어지는 두 문장과 랜덤 하게 추출된 두 문장을 넣고 BERT가 맞추도록 하는 작업

- 50% - sentence A,B가 실제 next sentence
- 50% - sentence A,B가 corpus에서 random으로 뽑힌(관계없는) 두 문장
- 97~98%의 accuracy 달성
- Fine-tuning Procedure
- Input pre-processing
- Pre-training 시의 Hyper Parameters
- Batch size: 16,32
- Learning rate(Adam): 5e-5, 3e-5, 2e-5
- Number of epochs : 2,3,4
3. Experiment
The General Language Understanding Evaluation(GLUE) Test results
- 모든 task에 대해 sota (state-of-art) 달성
- 데이터 크기가 작아도 fine-tuning에서 좋은 성능 기대

SQuAD v1.1 Test results

- 질문과 지문이 주어지고 그 중 substring인 정답을 맞추는 task
- 질문을 A embedding, 지문을 B embedding으로 처리
- 지문에서 정답이 되는 substring의 처음과 끝을 찾는 task로 문제 치환하여 해결
4. Conclusion
- 대용량 unlabeled data로 모델을 pre-training
- 특정 task를 가지고 있는 labeled data로 transfer learning을 하는 모델
- 특정 task를 처리하기 위해 새로운 network를 붙일 필요 X
- Bert모델 자체의 fine-tuning을 통해 해당 task의 state-of-the art 달성
- 양방향 구조를 통한 pre-train 모델 구축
- 번역 task나 language modeling과 같은 large-scale task는 모델 사이즈가 클수록 성능이 계속 상승하기 때문에 앞으로도 기대가치가 있다.
'ML 관련 > 자연어 처리 관련' 카테고리의 다른 글
| [논문 리뷰] SNS에서 단어 간 유사도 기반 단어의 쾌-불쾌 지수 측정 (0) | 2020.06.03 |
|---|---|
| [논문 리뷰] OpinionFinder: A system for subjectivity analysis (0) | 2020.05.23 |
| [논문 리뷰] Beating Atari with Natural Language Guided Reinforcement Learning (2) | 2020.04.13 |
| [논문 리뷰] XLNet : Generalized Autoregressive Pretrainingfor Language Understanding (0) | 2020.02.26 |
| [논문 리뷰] Attention is all you need (0) | 2019.12.05 |



댓글