https://web.stanford.edu/class/archive/cs/cs224n/cs224n.1174/reports/2762090.pdf
이번 게시글은 논문이 아닌 스탠포드의 자연어처리 기술, 딥러닝 강의인 cs224n의 2017년 spring에 프로젝트에서 1위를 차지한 학생들의 레포트이다.
레포트의 내용은 atari라는 게임에 강화학습, 자연어처리 기술을 활용하여 언어를 활용해 게임을 학습시켰다.
개인적으로 자연어처리를 활용하여 강화학습을 한다는 부분에 재미를 느껴 읽었으며 가볍게 읽기 좋은 수준이었다.
Introduction
학습의 3가지 종류
- 지도학습(Supervised Learning)
- training data set 에 Label(anwer,action)이 주어진 상태 학습
- 학습데이터를 통한 학습
- 새로운 입력에 대한 적절한 출력 기대
- 비지도학습(Unsupervised Learning)
- training data set에 Label이 주어지지 않은 상태 학습
- 목표 : unlabeled데이터의 hidden structure를 찾는 것
- 강화학습(Reinforcement Learning)
- 환경과의 상호작용을 통해 얻은 reward로부터 학습
- 목표 : Reward Maximize
- 기계 학습의 한 영역
- 현재의 상태를 인식, 선택 가능한 행동들 중 보상을 최대화하는 행동, 행동 순서를 선택하는 방법
- unlabeld data에서 숨은 구조 파악
- unlabeled data를 통한 action, rewardmaximize
Background
Markov Decision Process(MDP)
- 목표를 이루기 위해 상호작용으로부터 학습하는 문제 표현
- S - state
- a - action
- 각 state에서 어떤 action을 취할 경우 해당 action에 대한 점수를 취하며 점수의 도합이 특정점수(5점)가 되는순간 완성되는 과정
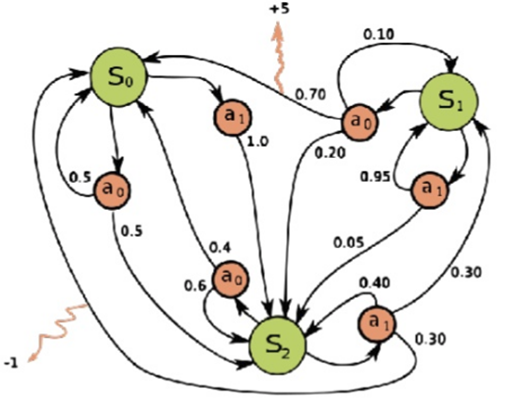
Sensation, action, goal
- Sensation - 환경이 어떤 상태(state)인지 인지
- Action - 주어진 상태(action)에 따라 행동(action) 결정
- Goal - 강화학습 문제의 목표(Goal) - 향후 시간에 따른 reward의 기하급수적 극대화
Approaches to Reinforcement Learning
- 매 시간 마다 환경으로부터 어떤 상태를 취하고 어떤 행동을 결정
- action과 외부 요인에 의해 영향을 받는 업데이트 된 상태 확인
- 종료 조건 충족까지 반복

The Action-Value Formulation
- Deep Q-Learning
- 각 가능한 액션에 대해 현재 상태를 입력 및 할인된 가치 추정하는 Q를 학습
- 테스트 시점에 Q-러닝 에이전트는 해당 상태에 대해 가장 높은 추정 값을 가진 action 선택
- 자신이 생각하는 최선의 행동의 활용과 다른 행동을 탐구하는 것의 균형 추구

The Action-Distribution Formulation
- Policy Iteration and A3C
- 해당 정책을 따르는 예측되고 discount된 보상을 최대화
- action에 할당된 확률 π의 로그를 곱한 것과 동일
- 업데이트에서 보상 R에서 추정된 상태 값, V(s)를 빼서 안정성을 높이며, 다른 사용 가능한 옵션보다 빠르게 수렴
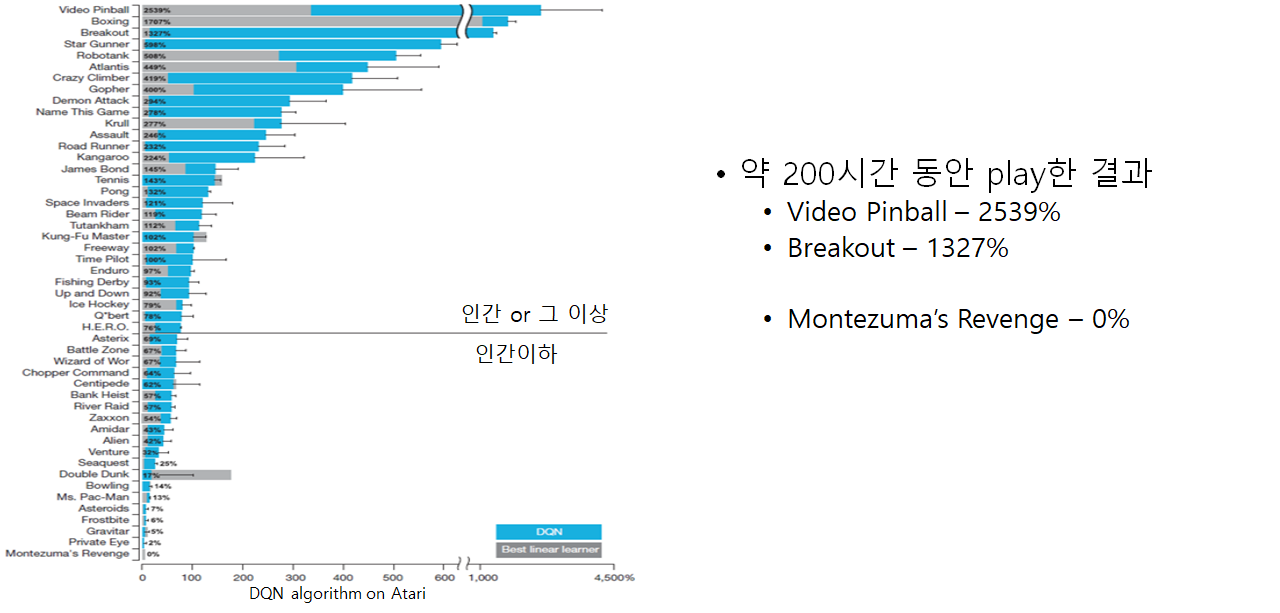
Deepmind의 DQN, 그리고 이후의 A3C는 많은 Atari게임을 성공적으로 풀어냈지만, Montezuma’s Revenge와 같이 sparse 한 reward를 가지는 문제는 아직 잘 풀지 못하고 있다.
이 문제를 풀기 위해 curiosity같은 개념의 additional reward를 주는 방법 시도

Approach and Experiments
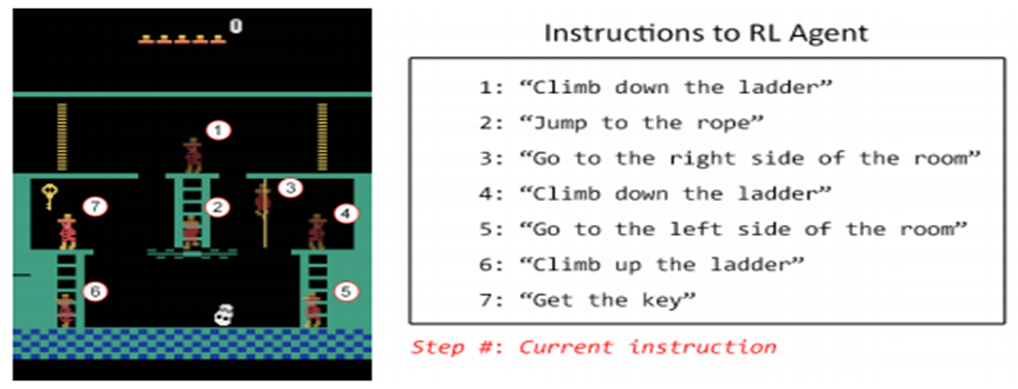
오른쪽 번호에 해당하는 행동을 하도록 자연어 지시를 통해 학습하는 강화학습 모델 훈련
MDP를 활용하여 게임의 각 부분을 나누어 학습하고자 하였으나 sparse한 보상을 갖고 있는 이와 같은 게임에서는 0%에 수렴하는 결과
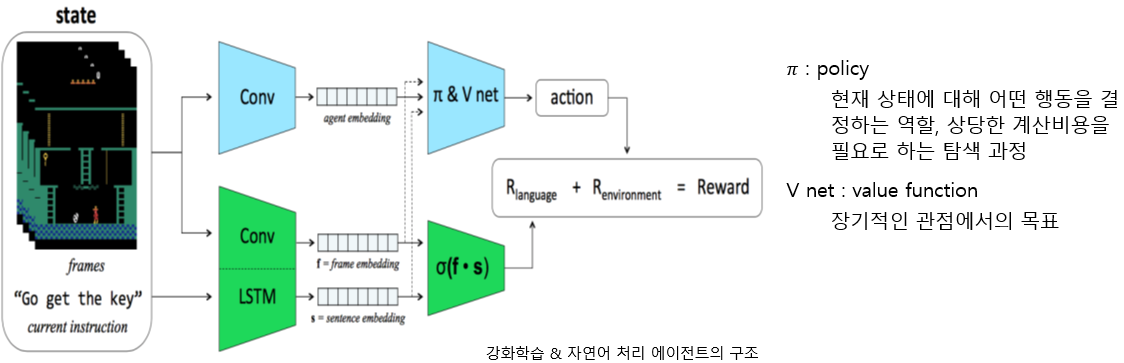
- Original A3C를 수행
- 얻어진 frame 수천개에 emplate matching code를 적용하여 분류
- 적절한 자연어 description(상황설명) 또는 Command(그 상황에서 해야 할 과업)을 부여
- 화면과 문장이 일치할 때 dot product이 높아지도록, 그렇지 않을 경우에는 낮아지도록 트레이닝
Conclusions
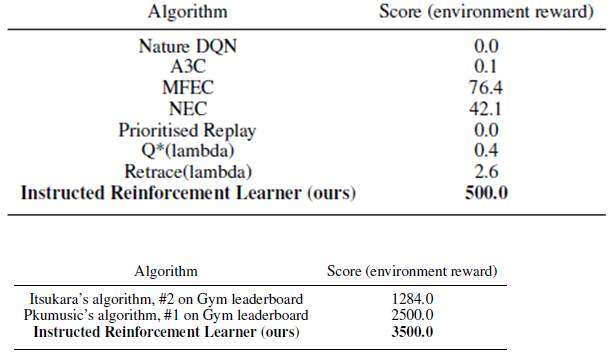
- 자연어 지시를 통해 학습하는 강화학습 모델을 훈련시키기 위한 새로운 틀을 제시
- Real World Robotics에 훨씬 효과적으로 적용 가능
- 다른 Auxiliary Rewarding 방식(Intrinsic Motivation 등)과 결합 가능성
'ML 관련 > 자연어 처리 관련' 카테고리의 다른 글
| [논문 리뷰] SNS에서 단어 간 유사도 기반 단어의 쾌-불쾌 지수 측정 (0) | 2020.06.03 |
|---|---|
| [논문 리뷰] OpinionFinder: A system for subjectivity analysis (0) | 2020.05.23 |
| [논문 리뷰] XLNet : Generalized Autoregressive Pretrainingfor Language Understanding (0) | 2020.02.26 |
| [논문 리뷰] Attention is all you need (0) | 2019.12.05 |
| [논문 리뷰] Bidrectional Transformers for Language Understanding(BERT) (4) | 2019.12.04 |



댓글