저자 : Ali Derakhshan, Hamid Beigy
Sharif Intelligent Systems Laboratory, Department of Computer Engineering, Sharif University of Technology, Tehran, Iran
이번에 포스팅할 논문은 이란의 수도 테헤란에서 쓰인 2019년에 논문이다. 이전에 포스팅했던 논문들과 유사하게 감정분석을 통해 주식시장을 분석하는 논문이며 이전 논문들과 다른점으로는 여러 사용들의 대조되는 의견들로 인해 분석하기 어려운 의견들에 대해 해결하는 방법을 다루었다. "Sentiment analysis on social media for stock movement prediction" - Nguyen et al(2015)라는 논문을 타겟으로 한 논문으로 해당 논문에서 나오는 제안 방법, 데이터셋, 파라미터까지 맞춰 비교하려는 모습을 많이 보였다.
#참고 사항
- 이란의 공용어는 페르시아어이다. 그 외에도 교육받은 사람들은 영어, 독일어, 프랑스어도 사용할 줄 안다.
- -- 출처 : 위키백과 --
본 논문에서는 이란의 주식시장 소셜 네트워크로부터 영어와 페르시아어로 된 두 개의 서로 다른 데이터셋에서 사용자의 의견을 추출하여 테스트하기 위한 음성 부분 그래픽 모델을 도입하였으며 모델 기반 의견 마이닝의 문제점을 다루고 있다.
Introduction
주가 예측 능력은 기업, 학계에서 많은 관심을 갖는 주제이지만 쉽지 않으며 달성하기 어렵다. 현재 주식시장에서의 주주들의 감정(긍정, 부정)은 그 주식의 미래 가치를 보여주는 필수적 지표로 평가되고 있으며 최근 몇 년 동안 인터넷, 소셜 네트워크 등의 확장으로 회사의 주식에 대한 사용자의 의견이 상당히 많아졌다.
주가는 다양한 뉴스를 포함한 많은 요인의 영향을 받지만 본 논문의 초점은 사용자의 감정분석에 있다. 따라서 본 논문에서는 소셜 미디어의 사용자 의견만을 사용하여 최상의 정확도를 달성하는 것이 목표이다.
본 논문의 목표는 소셜 미디어의 사용자 의견만을 사용하여 다음날 주식 시장 변동을 예측하는데 사용할 수 있는 모델을 개발하는 것으로 제안한 모델에서는 1~2일 연속으로 추출된 feature를 사용하여 다음 날 가격을 예측하기 위해 supervised 모델을 학습하였다.
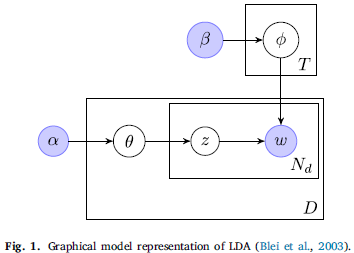
품사 태그를 기준으로 단어를 분리하는 LDA모델에서 품사를 사용하였으며 제안된 방법을 LDA-POS라고 부른다. 이 모델은 두 개의 데이터셋(영어, 페르시아어)를 사용하였다.
- 영어 데이터셋은 Nguyean paper에서 (1년 이상 18개 종목 주석 포함)가져와 사용하였다.
- 페르시아어 데이터 셋은 6개월 동안 이란의 주식시장에서 5개의 주식에 대한 의견이 들어간 페르시안 데이터를 수집하였다.
Related work
주식 시장을 예측하는 문제의 핵심은 EMH, random walk theory 등의 연구에 따라 주가 변동을 전혀 예측할 수 없다는 것이었지만, 일부 연구에서 주가 변동은 예측 가능하며 EMH, random walk theory등을 따르지 않음을 보여주었다.
위 2개의 이론 외 주식 거래에는 fundamental analysis, technical analysis이라는 2가지 주요 철학이 존재한다.
- fundamental analysis - 회사의 경제 상황 및 경제 지표는 해당 회사의 전반적인 상태를 평가하고 주가 예측시 사용
- technical analysis - 일정 시간 동안 주식 가격 내역을 분석하여 이를 기반으로 예측
기존 연구자들은 technical analysis 만을 활용하여 historical data만을 사용하였으며 주목할만한 성능을 보인 연구는 거의 없었다.
주식 시장 예측을 개선하기 위해 텍스트 데이터를 포함시키려는 작업이 있었고 이 작업에서 사용 가능한 텍스트 데이터의 출처로 경제뉴스, 소셜미디어를 활용하였다.
감정분석은 서로 다른 특징의 측면을 분리하고 극성을 개별적으로 결정하는것이 중요하며 이 영역에 대한 일부 연구는 명사가 측면, 근처의 형용사는 그 측면에 대한 극성을 나타낸다는 아이디어를 바탕으로 작업하였다.
opinion mining에 대한 다른 접근방식으로 argumentation based opinion mining 이 있으며 argumentation은 진술을 뒷받침, 모순 관계에 대해 설명 가능하며 논증 관계를 그래프 형태로 제시하여 이를 근거로 결정을 내릴 수 있도록 한다. 이 분야의 최근 논문은 논증 이론과 자연어 처리 방법을 결합하였으며 가장 논쟁의 여지가 있는 논증을 찾고 사용자가 보다 좋은 결정을 내릴 수 있도록 하였다. " The introduced model combines Argumentation and Aspect-Based Opinion Mining "(Dragoni et al.,2016)
금융 영역(Kumar 및 Ravi, 2016)의 텍스트 마이닝 응용에 대한 설문 조사에 따르면, 금융 분야의 연구 약 70%가 decision tree, SVM, regression analysis와 같은 정규 방법을 사용하였으며 최근 연구들에 따르면 복잡한 모델 사용시 일반적으로 성능이 저하된다는 결과가 있다 이에 따라 일반적 방법으로는 다른 방법과 동일하게 사용하였다.
시장 예측을 위해, 대부분의 연구는 텍스트에서 추출한 특징을 충분히 찾지 못했고, 그들은 대개 특징 수준이나 의사결정 수준에서 예측을 견고하게 하기 위해 숫자 경제 데이터를 그 특징에 결합시키거나 합하는 방법을 사용했다(Xing et al., 2018b).
Dataset
이 논문에서 사용된 데이터 타입은 2종류 주식 social network의 데이터셋(페르시아어, 영어 comment 분석), 주당 일일 가격 시장 데이터이다.

Mehods for stock movement prediction
주가를 예측하기 위해 일련의 특성(다른 방법 사용)을 매일 추출한 다음, 각각 주가의 상승과 하락을 나타내는 두 가지 범주로 특징을 분류하여 가격 움직임을 예측하는 SVM(Support Vector Machine)을 사용하였으며 공정한 비교(Nguyen과의 비교)를 위해 언급된 기사와 같은 매개 변수와 예측 모델 유지
Price only method
주식 history data 만을 사용하여 과거 가격만으로 시장 예측이 가능한지에 대한 방법
- pricet-1 - 각 거래 날짜에 대해 이전 날짜 하나의 가격 변동(상,하)
- pricet-2 - 이전 날짜
- En - 영어
- Per - 페르시아어

Human sentiment method
영어와 페르시아어 데이터 셋은 사용자들이 그들의 의견을 표현하는 몇몇 코멘트로 구성
해당 커뮤니티 이용자들은 자신의 의견을 명시적으로 표시함으로써 주식에 대한 낙관적 또는 비관적 개요를 명시적으로 판단
특정 주식에 대한 이용자의 의견을 가장 잘 보여주는 특징
- 영어 데이터셋의 레이블은 강력한 판매, 판매, 보류, 구매, 강한 구매
- 페르시아 데이터셋의 레이블은 구매, 판매로만 구성
각 거래일에 페르시아 데이터셋의 라벨(구매,판매)의 메시지 수를 세어 백분율을 사용하였으며 이를 토대로 다른 레이블의 비율을 확인하여 각 거래 날짜에 대해 현재, 이전 거래 날짜에 대해 명시적으로 레이블이 지정된 메시지 중 구매 레이블의 백분율을 계산, 각각 HsentP eri,t / HsentP eri,t-1로 표시
각 거래 날짜에 대한 각 레이블의 백분율이 계산되며 5%가 인간의 감정을 나타냄
LDA-based method
모든 문서(우리 모델의 메시지)를 잠재 주제의 혼합물로 간주하는 Latent Dirichlet Allocation의 생성 확률 모델에 기초하며 각 주제는 단어에 대한 확률 분포이다. 본 논문에서는 이 모델을 기준 모델로 사용하였으며, 참조 모델(Nguyen)과의 비교를 하였다. - 비교를 위해 동일한 매개변수 값 사용

영어 데이터셋에 대한 예측모델 feature - priceEnt-1/priceEnt-2/HsentEni,t/HsentEni,t-1
페르시아 데이터 세트의 예측모델 feature - ldaP eri,t
Aspect-based sentiment
데이터 집합에서 모든 메시지에서 연속된 명사를 자주 검출(10개 이상)한 다음, 주제라고 하는 이들 공통 연속 명사의 감정 극성을 결정
각 주제의 감정 점수를 찾기 위해 SentiWordNet(해당 주제의 극성을 가진 opinion 단어 목록)을 사용하여 해당 주제가 포함된 문장에서 각 의견 단어의 거리, 극성에 기초하여 주제에 대한 점수를 매긴다(보다 빈번한 주제의 중요성을 강조하기 위해, 해당 주제가 있는 메시지의 백분율도 이 방법의 특징으로 포함)
- I - 예측 모델에 해당하는 중요성
- t, t-1 - 각 거래 날짜 t,t-1
# 페르시아어의 단어는 약 1500단어이며 페르시아어로 된 의견을 이해, 유사성 감지에 대한 작업은 페르시아어 사전을 확장해야하며 동의어가 너무 많기 때문에 페르시아어로는 구현하지 않았다. #
- LDA-POS Method
본 논문에서 제안하는 방법이다.
기존 LDA기반 방법에서는 데이터셋에서 정지 단어 제거후 서로 다른 주제의 분포를 평가한다.
본 논문의 LDA기반 방법에서는 데이터셋에서 정지 단어를 제거하는 대신 문장에 있는 모든 단어의 품사를 결정 후 POS의 4가지 카테고리 태그를 가진 단어를 해당 POS의 문서로 그룹화하여 나눈다. 각 주제가 특정 주제에 포함된다고 가정하여 사용한다.
POS태그의 각 주제는 단어의 분포이며 데이터셋의 training 부분과 일부 POS태거( ) 를 사용하여 각 POS 카테고리의 문서를 생성한다.


데이터셋의 훈련일에 각 거래날짜에서 모든 메시지의 문장에서 단어의 품사역할을 사용, 결정
영어 품사 부분 태그지정 및 표기를 위해 StanfordCoreNLP를 사용한 후 가진 단어들을 어휘화 및 언어부분에 해당하는 문서에서 단어들 분류(동일 언어 카테고리)
데이터셋의 훈련부분에서 각 거래일에 대해 카테고리 생성 후 카테고리 내 1,000번 반복, Gibbs샘플링을 사용하여 주제 추론
각 품사 카테고리에 대해 50개의 주제 선택, 각 거래 날짜에 대한 데이터셋의 서로 다른 품사 카테고리에서 각 주제의 확률 계산
각 거래 날짜에 대해 이 방법으로 생성된 feature는 각 동사,형용사,전치사,명사(품사) 카테고리에 대해 50개의 주제 확률입니다.
POS 카테고리를 분류하고 모든 카테고리의 주제를 포함하는 각 거래 날짜에 대해 200개의 차원으로 feature vector를 작성, 일부 주제의 경우 일부 주식에 대한 확률이 매우 낮아 SVM분류기의 성능에 문제가 발생 가능하므로 각 주식의 feature vector에 feature 선택 메커니즘을 수행하여 training set에서 shape의 평균 계산, 정사각형이 0.03보다 크면 shape vector에 shape 유지
Neural network method
선형 커널과 SVM 사용 대신 신경망 모델을 사용
하나의 hidden layer를 가진 2층 신경망 사용
hidden layer의 activation function - tanh
output layer의 activation function - sigmoid
LDA의 주제는 50개이므로 신경망의 입력층 크기는 50
출력층의 경우 다음 날 가격 상승,하락에 해당하는 0,1중 하나를 출력(sigmoid)
출력이 0.5보다 크면 1(클래스)
출력이 0.5보다 크지 않으면 0(클래스)
hidden unit - 40개
반복 횟수 1만개 학습률 0.1
Experimental results
Evaluation measure
페르시안,영어 데이터셋을 각각 테이터셋, 트레이닝 셋으로 나눈다.
영어 데이터셋
- 12.7.23~13.3.28 트레이닝용 / 171개의 거래 날짜 포함
- 13.4.1~13.7.19 테스트용 / 78개의 거래 날짜 포함
페르시아 데이터셋
- 16.4.30~16.8.28 트레이닝용 / 76개의 거래 날짜 포함
- 16.9.2~16.11.2 테스트용 / 30개의 거래 날짜 포함
$ Accuracy = {tp+tn \over tp+fp+fn+tn} $
- tp - true positive
- tn - true negative
- fp - false positive
- fn - false negative
The results
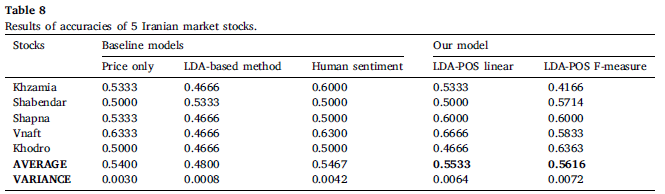
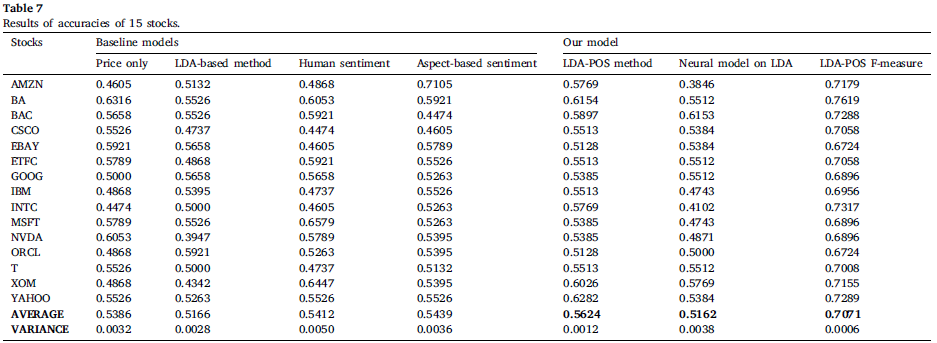
표 7과 표 8은 영어와 페르시아어 데이터 세트에 대한 서로 다른 주식의 정확도를 표기(모든 주식에 대한 평균,분산 제공)
LDA-POS 방식을 사용하여 영어 데이터셋의 15개 종목에서 56.24%의 전체 평균 정확도와 페르시아 데이터셋의 5개 종목에서 55.33%의 전체 평균 정확도에 도달
상당한 주식 수와 비교적 장기간에 걸쳐 서로 다른 언어로 된 두 개의 데이터셋에 대해 방법을 구현하여 일부 종목에서 target이 되는 논문의 모델보다 더 좋은 정확성을 가짐
이 정확도가 정말 주가 움직임 예측을 나타내는 정확도인지 알기 위해 인간 감정의 결과와 LDA-POS 방식을 비교하였으며 영어 데이터셋에서는 인간 감정이 0.26% 더 좋고 LDA-POS 방법은 2.38 좋다
페르시아 데이터셋에서는 인간 감정에서 0.67% LDA-POS방식에서는 2.33 좋다
따라서 소셜 미디어에서 감정 정보를 사용하는것이 주식 시장 예측에 도움이 된다고 추론한다
본 논문에서는 주제 모델링 방법에 스피치 부분 태그를 통합하는 LDA-POS라는 방법을 제안하였으며 영어, 페르시아어 데이터셋을 사용 각각 56.24%, 55.33%의 결과를 얻었다.
'ML 관련 > 주식 시장 관련 논문' 카테고리의 다른 글
| [논문 리뷰] 뉴스 텍스트 마이닝과 시계열 부석을 이용한 주가예측 (0) | 2020.06.04 |
|---|---|
| [논문 리뷰] Stock Market Trend Prediction with Sentiment Analysis based on LSTM Neural Network (0) | 2020.05.05 |
| [논문 리뷰] CNNpred: CNN-based stock market prediction using a diverse set of variables (2) | 2020.04.17 |
| [논문 리뷰] Twitter mood predicts the stock market (1) | 2020.02.21 |
| [논문 리뷰] Stock Market Prediction A Big Data Approach (0) | 2020.02.18 |




댓글