이번 논문도 이란에서 쓰인 논문이다. (이란이 시장예측에 관심이 많나보다...)
본 논문은 시장예측에서 중요하게 활용되는 feature extraction을 위해 다양한 시장, 출처의 데이터 모음에 적용 가능한 CNN-based 프레임워크를 제안했다.
세계증시에 대한 설명에 한국의 시장이 잠깐 언급된다....기분이 좋았다....ㅎㅎ
- 저자 : Ehsan Hoseinzade, Saman Haratizadeh
- 저널 : Expert Systems With Applications
- article history : Received 6 September 2018
Introduction
- 주식시장은 경제성장의 매우 중요한 역할을 수행하기에 시장예측은 매우 중요하다.
- 대부분의 거래 모듈의 목표는 해당 포트폴리오의 주식 위험과 관련하여 전체 수익률을 극대화하는 주식 포트폴리오를 만드는 것이며 예측 모듈은 시장예측에 초점을 맞추고 있다.
- 이러한 모듈의 성능, 거래 시스템은 예측의 정확성에 의해 큰 영향을 받으며 이는 거의 불가능하다.
- 성능이 좋은 모듈을 위해선 다양한 변수들을 모두 이해하며 활용해야 하지만
- 기존 CNN을 활용한 feature extraction에 대한 연구가 있었지만 history만을 바탕으로 예측하는 1차원적 입력에 그쳤다.
- 기존 시장예측- 다른 종목간의 상관관계 고려X
- 본 논문에선 1차원적 입력에 그치지 않고 CNN에 기반한 3차원적 입력을 통합하여 사용하는 프레임워크를 제안하였다.
Related works & Background
- 기존 연구들은 다변수보단 하나의 변수에 초점을 맞춰 사용하였으며 feature extraction의 방법으로 기존ANN(articifical neural network)에서 최근 CNN(convolution neural network)를 사용, Prediction methods의 방법으로 ANN SVM(ann support vector machine)에서 CNN으로 활용되고 있다.

Proposed CNN: CNNpred
- 제안한 방법 CNNPred는 2D-CNNPred와 3D-CNNPred로 재조정된 두 가지 변형을 가지고 있으며 입력 데이터의 표현, 일일 feature extraction, 지속적 feature extraction, 최종 예측의 네 가지 주요 단계로 나눈다.
입력 데이터의 표현 : 2D-CNPred와 3D-CNNPred는 예측 모델 구축을 위해 서로 다른 접근방식 사용

2D-CNNpred : 기존 접근방식(과거 - 미래 매핑)은 그대로, 다른 시장의 정보들을 사용, 모든 정보를 종합하여 2차원 tensor를 input 으로 하여 학습
3-D CNNpred : 각 예측 모델은 여러 시장의 historical 정보를 사용한다고 가정, 3D-CNNPred에서 각 예측 모델은 이용 가능한 모든 정보를 입력/ 여러 시장의 historical data를 feature extraction하여 각 시장에 대한 별도의 예측모델 학습
일일 feature extraction
- 시장예측의 전통적 방식 - daily historical data를 활용한 candlestick(캔들차트) 분석,
- CNNpred의 방식 - historical한 daily variable들을 더 높은 수준의 feature로 결합하여 convolution계층으로 연산
지속적 feature extraction
- 시장의 미래 행동을 예측하는 데 유용한 다른 정보들은 시간의 경과에 따른 시장의 행동을 연구하는데서 오며 시장의 행동에 나타나는 경향에 대한 정보를 줄 수 있고 그것을 바탕으로 미래를 예측할 수 있는 패턴을 찾을 수 있다.
- 따라서 연속 데이터일수의 변수를 결합해 동향을 나타내거나 시장의 행동을 일정 시간 간격으로 반영하는 고도의 feature을 모으는 것이 중요
- 2D-CNNpred와 3D-CNNpred데이터 모두 첫 번째 계층에서 추출된 feature를 결합하도록 되어 있는 계층을 가지고 있으며 일정 시간 간격으로 데이터를 요약한 훨씬 더 정교한 feature를 만들어 낸다.
최종 예측
- 이전 계층에서 생성된 feature는 평탄화 연산을 사용하여 1차원 벡터로 변환되고 이 벡터는 feature 예측에 매핑하는 완전 연결 계층에 공급
2D-CNNpred
- 입력 표현 : 2차원 matrix (행렬의 크기 - historical 의 일 수, 각 날을 나타내는 변수의 수에 따라 달라짐)
- 예측에 사용된 입력이 각각 f(변수)에 의해 표현되는 d일로 구성된 경우 삽입 텐서의 크기는 (d × f)
일일 feature extraction
- 2D-CNPred에서 일일 feature 추출을 위해 초기 변수 필터 1×숫자를 사용
- 각각의 필터는 모든 일별 변수를 포함하며 이를 하나의 상위 수준의 feature로 결합 가능
- 2D-CNNPRED는 이 계층을 사용하여 다른 조합의 1차 변수 구성 가능
- 네트워크가 필터에 해당하는 가중치를 0과 동일하게 설정하여 쓸모없는 변수를 떨어뜨리는 것도 가능
- 따라서 이 레이어는 초기 feature 추출/ feature 선택 모듈로 작동

지속적 feature extraction
- 2D-CNNPred 추출물의 첫 번째 층은 일차 변수에서 벗어나지만, 다음 계층은 다른 날의 추출된 feature를 결합하여 특정 기간 동안 사용 가능한 정보를 집계하기 위한 더 높은 수준의 feature 구성
- 첫 번째 레이어로서, 이러한 후속 레이어들은 입력에서 더 높은 레벨로 낮은 레벨의 feature를 결합하기 위해 필터 사용
- 2D-CNPRED는 두 번째 레이어에서 3 ×1 필터를 사용 (각각의 필터는 3일 연속이며, 이것은 삼선 스트라이크, 삼흑 까마귀와 같은 유명한 촛불 막대 패턴의 대부분이 3일 연속으로 의미 있는 패턴을 찾으려고 한다는 관찰에서 영감을 받은 설정)
- 세 번째 계층은 풀링 계층에 매우 일반적인 설정인 2 ×1 최대 풀링을 수행하는 풀링 계층
- 이 풀링 레이어 이후 그리고 더 긴 시간 간격으로 정보를 집계하고 훨씬 더 복잡한 형상을 구성하기 위해 2D-CNNPred는 3×1 필터를 가진 또 다른 콘볼루션 레이어를 사용하고 그 다음에 첫 번째와 같은 다른 풀링 레이어를 사용
최종 예측
- 마지막 풀링 계층에서 생성된 feature는 최종 feature vector로 평탄화
- 이 feature vector는 fully connected layer를 통해 최종 예측에 반영
- 활성화 함수 - sigmoid
- 각 예측에 사용한 입력은 각각 82개의 변수로 표현된 60일로 구성
- 입력 - 가로 60, 세로 82의 행렬
- 첫 번째 콘볼루션 계층은 8개의 1 ×82 필터를 사용
- 8개의 3x1 필터, 2개의 convolution layer
- 각각 2x1 최대풀링 계층
- 최종 평탄화 feature vector에는 최종 출력을 생성하기 위해 fully connected layer에 공급되는 104개의 feature 포함

3D - CNNPred
입력 데이터의 표현 -3차원 텐서를 사용(여러 시장 데이터 포함)
3차원 텐서 사용 - (각 샘플에 여러 시장의 정보 포함)
목표 - 과거 j일을 기준 day t 예측

일일 feature extraction
첫 번째 필터 층은 1 ×1 컨볼루션 필터 세트로 정의

네트워크는 feature 선택/추출 알고리즘의 역할을 할 수 있는 기능
지속적 feature extraction
일일 변수 외에도, 3D- CNNpred의 입력 데이터는 다른 시장에 대한 정보를 제공
- 다음 4개 계층은 데이터의 변동 패턴을 시간에 따라 요약하는 상위 레벨 feature 추출
- 두 번째 컨볼루션 계층의 필터 폭은 모든 관련 시장을 포괄하는 방식으로 정의
- 필터의 높이는 3으로 선택되어 3회 연속 시간 단위를 커버 (2D-CNNPred와 마찬가지로)
- 두 번째 컨볼루션 계층의 필터의 크기 3 × number of market
- 다음 3개 계층은 2 ×1 최대 풀링 계층, 또 다른 3 ×1 최대 풀링 계층에 이어 최종 2 ×1 최대 풀링 계층으로 정의
최종 예측
지속적 feature extraction 단계의 출력을 평탄화하여 최종 결과를 도출하는 데 사용
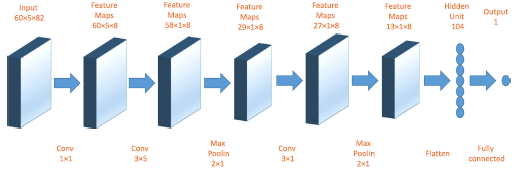
3D-CNNPRED의 샘플 구성 :
- 입력 - 깊이 82의 60 X 5의 행렬
- 첫 번째 컨볼루션 계층은 8개의 필터를 사용하여 1 ×1 콘볼루션 작동을 수행
- 그 다음에는 8개의 3 ×5 필터와 2 ×1 최대 풀링 계층을 가진 하나의 컨볼루션 계층
- 또 다른 콘볼루션 계층은 8개의 3 ×1 필터를 사용하고, 다시 2 ×1 최대 풀링 계층에 의해 낮춘 경우 최종 104개의 feature 생성
- fully connected layer가 104개의 뉴런을 1개의 뉴런으로 변환시켜 최종 산출물 출력
Experimental settings and results
연구에서 사용된 데이터셋 :
- S&P 500 지수 종가의 일일 방향, 나스닥 종합 지수, 다우존스 산업 평균, NYSE 종합 지수, 러셀 200 등
- 2010년 1월부터 2017년 1월까지
- 60% training / 20% validation / 20% test
- 각 표본에는 이미 설명된 82개의 변수가 있으며 할당된 라벨은 Eq (5)에 따라 결정(여기서 근접 t는 day t의 마감 가격)

- data normalization를 위해 Eq(6) 사용

- $\bar{x}$ - 정규화된 변수 벡터
- $x_{old}$ - 원래 변수 벡터
- $\bar{x}$, $\sigma$ - 원래 변수의 평균, 표준편차
Evaluation methodology
- Macro-Averaged-F-measure사용
Parameters of network
- 케라스활용
- 마지막 Sigmoid를 제외한 모든 층의 활성화 함수로 RELU 사용
- 네트워크 훈련 - 배치 크기 128 Adam 사용
Results


conclusion
- CNNpreed는 F-measure 측면에서 기준 알고리즘에 대한 5가지 모든 변수의 예측 성능을 약 3%~11% 향상
- 이 논문의 주요 목적은 주식시장의 움직임을 예측하는 것이었지만 소소한 상승, CNNpred는 무역 시스템에서 성공적으로 사용
- 앞으로의 연구방향으로 무역 시스템에 활용될 목적으로 CNNpred에 대한 추가 조사, 유망한 연구 방향으로 할 논문
'ML 관련 > 주식 시장 관련 논문' 카테고리의 다른 글
| [논문 리뷰] 뉴스 텍스트 마이닝과 시계열 부석을 이용한 주가예측 (0) | 2020.06.04 |
|---|---|
| [논문 리뷰] Stock Market Trend Prediction with Sentiment Analysis based on LSTM Neural Network (0) | 2020.05.05 |
| [논문 리뷰] Sentiment analysis on stock social media for stock price movement prediction (0) | 2020.04.06 |
| [논문 리뷰] Twitter mood predicts the stock market (1) | 2020.02.21 |
| [논문 리뷰] Stock Market Prediction A Big Data Approach (0) | 2020.02.18 |




댓글