 CHAPTER 5 순환 신경망(RNN)
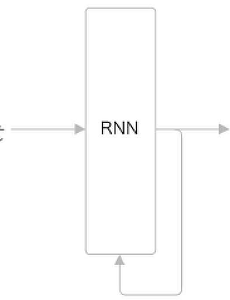
4장까지의 신경망 - feed forward(흐름이 단방향인 신경망) 구성 단순 이해 쉬움 응용 쉬움 시계열 데이터를 잘 다루지 못함 순환 신경망(Recurrent Neural Network)(RNN) 순환하는 경로(닫힌 경로) 순환 경로를 따라 데이터 순환 과거의 정보를 기억 및 최신 데이터로 갱신 가능(시계열 데이터에 적합) $x_{t}$ - 각 시간에 입력되는 벡터( t : 시각 ) 입력 값 - $x_{0}, x_{1},x_{2}, ..., x_{t}, ...)$ 출력 값 - 입력에 대응하여 $(h_{0}, h_{1}, ..., h_{t}, ...) $ 각 시각의 RNN계층은 그 계층으로부터의 입력, 1개 전의 RNN계층으로부터의 출력을 입력받음 -> 두 정보를 바탕으로 현 시각의 출력을 계산 계산..
2020. 2. 18.
CHAPTER 5 순환 신경망(RNN)
4장까지의 신경망 - feed forward(흐름이 단방향인 신경망) 구성 단순 이해 쉬움 응용 쉬움 시계열 데이터를 잘 다루지 못함 순환 신경망(Recurrent Neural Network)(RNN) 순환하는 경로(닫힌 경로) 순환 경로를 따라 데이터 순환 과거의 정보를 기억 및 최신 데이터로 갱신 가능(시계열 데이터에 적합) $x_{t}$ - 각 시간에 입력되는 벡터( t : 시각 ) 입력 값 - $x_{0}, x_{1},x_{2}, ..., x_{t}, ...)$ 출력 값 - 입력에 대응하여 $(h_{0}, h_{1}, ..., h_{t}, ...) $ 각 시각의 RNN계층은 그 계층으로부터의 입력, 1개 전의 RNN계층으로부터의 출력을 입력받음 -> 두 정보를 바탕으로 현 시각의 출력을 계산 계산..
2020. 2. 18.





